LoRA 外的其他微调方法
Adapter类
PEFT技术通过在预训练模型的各层之间插入较小的神经网络模块,这些新增的神经模块被称为"适配器",在进行下游任务的微调时,只需对适配器参数进行训练便能实现高效微调的目标。
在此基础上衍生出了AdapterP、Parallel等高效微调技术;
Adapter Tuning
设计了Adapter 结构,将其嵌入 Transformer 的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构进行微调。
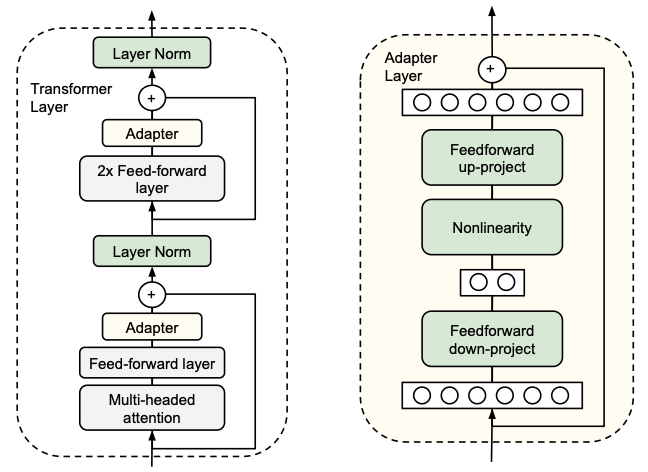
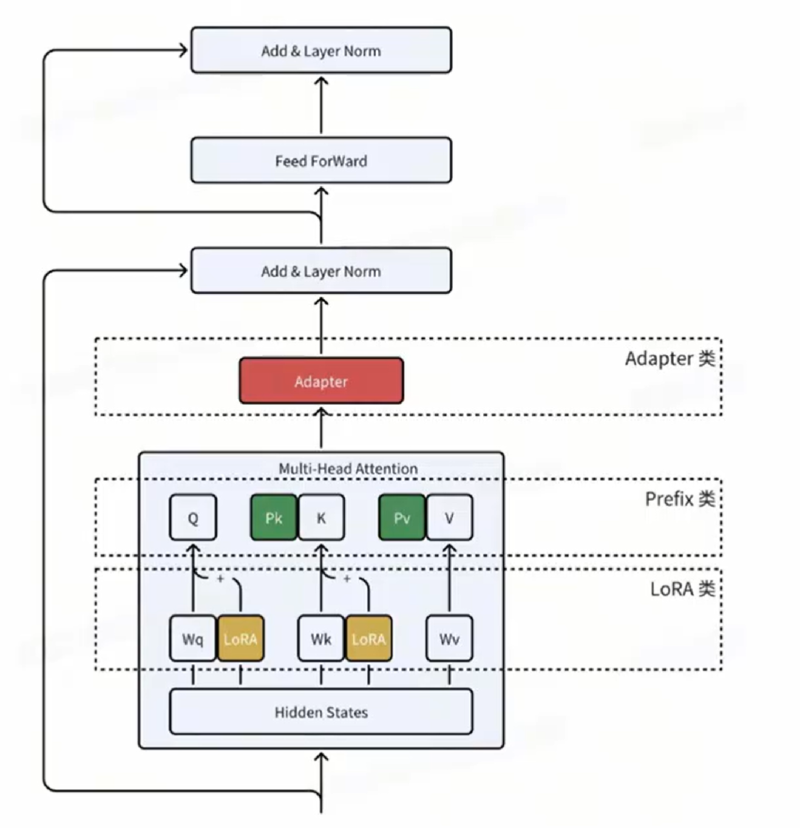
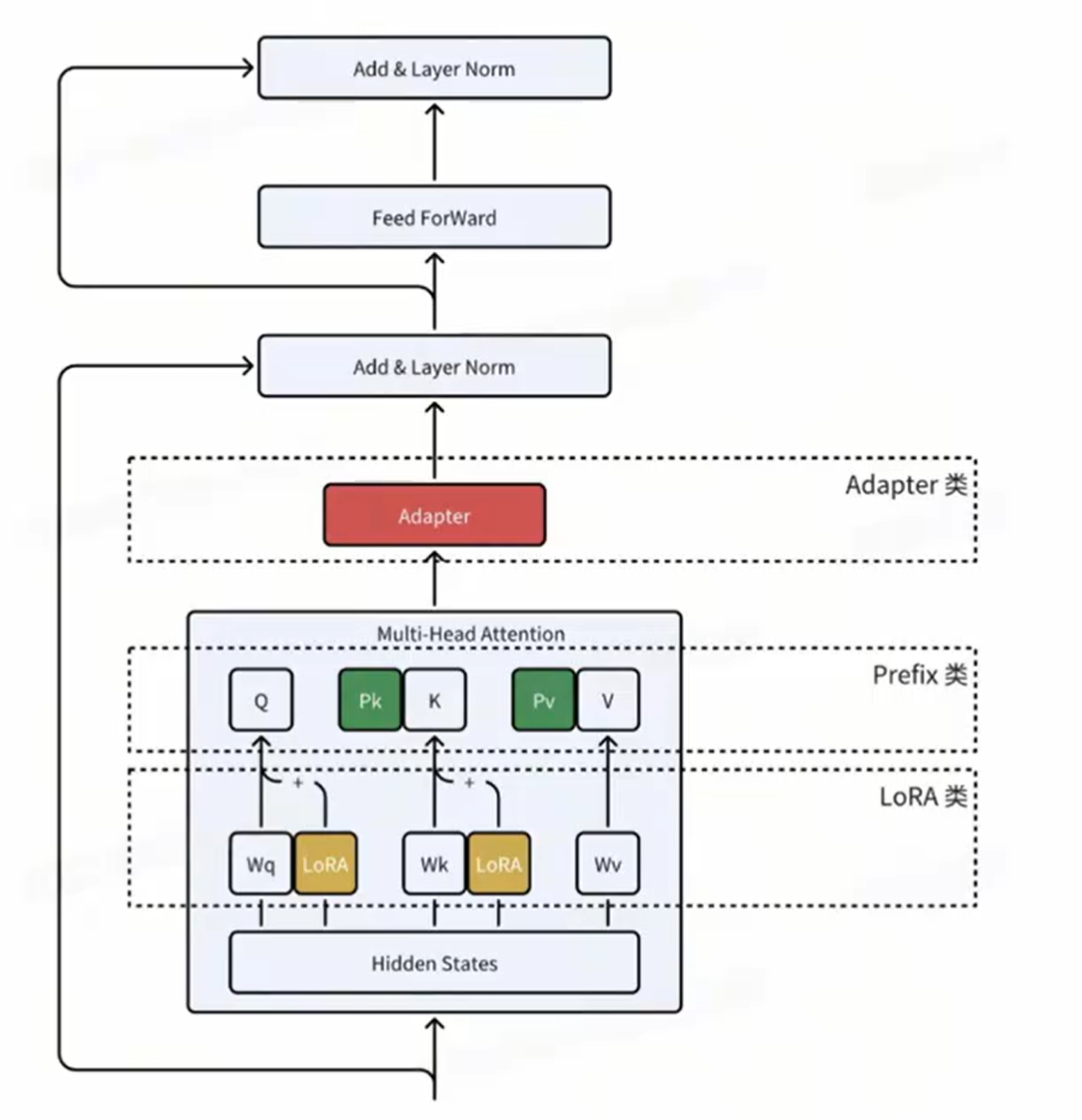
- 首先是一个 down-project 层将高维度特征映射到低维特征
- 然后过一个非线形层之后,再用一个 up-project 结构将低维特征映射回原来的高维特征
- 同时也设计了 skip-connection 结构,确保了在最差的情况下能够退化为identity(类似残差结构)
能够在只额外对增加的 3.6% 参数规模(相比原来预训练模型的参数量)的情况下取得和Full-Finetuning 接近的效果(GLUE指标在0.4%以内)。
首次提出针对 BERT 的 PEFT微调方式,拉开了 PEFT 研究的序幕。
遗留问题:增加了模型层数,引入了额外的推理延迟。
PrefixTuning类
PEFT技术通过在模型的输入或隐层添加k个额外可训练的前缀标记,模型微调时只训练这些前缀参数便能实现高效微调的目标。
在此基础上衍生出了P-Tuning、P-Tuningv2等高效微调技术;
Prefix-Tuning
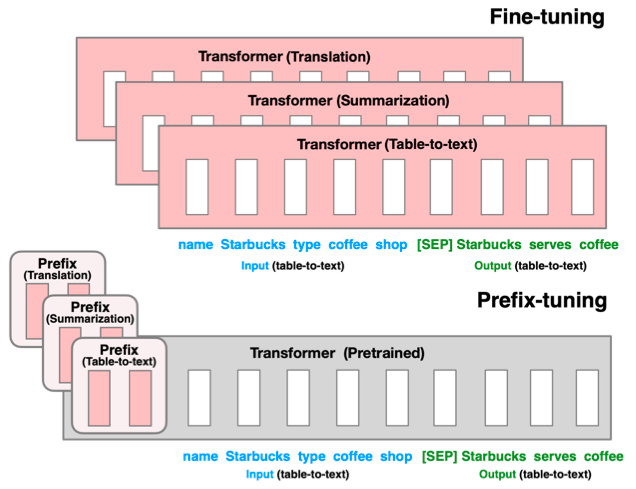
该方法是在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。
遗留问题:难于训练,且预留给 Prompt 的序列挤占了下游任务的输入序列空间,影响模型性能。
遗留问题:Prompt Tuning和P-tuning这两种方法都是在预训练模型参数规模够足够大时,才能达到和Fine-tuning类似的效果,而参数规模较小时效果则很差,且在sequence tagging任务上表现都很差。
LoRA 及 LoRA 变体
对于解决许多问题来说,我们希望在给定的下游任务上训练LLM,例如对句子进行分类或生成给定问题的答案。但是如果直接使用微调,这就需要要训练有数百万到数十亿个参数的大模型。
LoRA提供了另一种训练方法,通过减少训练的参数数量,这种方法更快、更容易进行。LoRA引入了两个矩阵A和B, 如果参数W的原始矩阵的大小为d × d,则矩阵A和B的大小分别为d × r和r × d,其中r要小得多(通常小于100)。参数r称为秩。LoRA 使用两个矩阵的乘积来模拟模型的参数变化。
如果使用秩为r=16的LoRA,则这些矩阵的形状为16 x d,这样就大大减少了需要训练的参数数量。
LoRA的最大的优点是,与微调相比,训练的参数更少,但是却能获得与微调基本相当的性能。
LoRA及其变体概述:LoRA, DoRA, AdaLoRA, Delta-LoRA-阿里云开发者社区
LoRA
引入两个低秩矩阵 A(dr)、B(rd),冻结其余参数,使得微调的参数量大大减少
A 被初始化为均值为 0 的正态分布,B 初始化为全 0
LoRA+
B 的学习率设置为远高于 A,使训练更加高效
LoRA-FA
A 在初始化后被冻结,只训练 B,使得参数减半
LoRA-drop
x 作为隐藏层状态,利用 BAx 计算 LoRA 适配器的重要性,如果重要性较小则将其进行冻结
AdaLoRA
对不同位置的 LoRA 适配器分配不同的秩
DoRA
将矩阵中的向量分解成大小和方向的乘积,获得更高的准确度