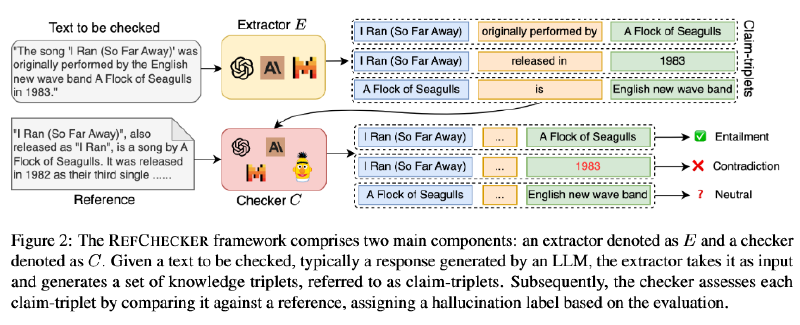
三元组、检索外部事实
Motivation
目前不同细粒度:
- response: 但当响应复杂且冗长时,它可能不具备信息性,并且在幻觉是局部时可能导致假阴性
- sentence: 无法跨句子捕捉知识
- sub-sentence: 结构上难以定义,用于 in-context learning 的高质量 demo 难以定义
提出将知识表示为三元组claim-triplets: (subject, predicate, object),
Conclusion
三元组比其他粒度提升 9%
基准 KNOWHALBENCH:7 个 LLM 的 2100 个回答,标注了 11k 个三元组
自动检测框架 REFCHECKER:相比之前的方法在一致性上提升了 6.8% 至 26.1%
Related Work
Method
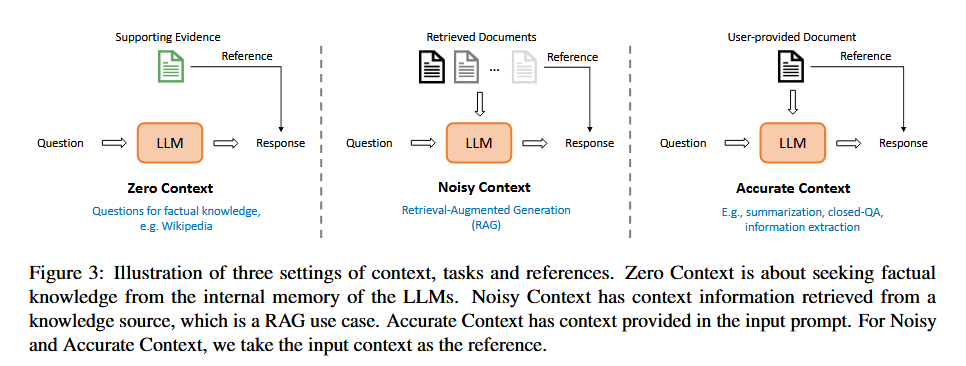
三种上下文:
Zero-Context: closed book QA, 基于 LLM 内部知识回答
Noisy Context: 包含噪声,RAG 等获取外部知识
Accurate Context: 无噪声,针对文本摘要、closed-QA、信息抽取等任务
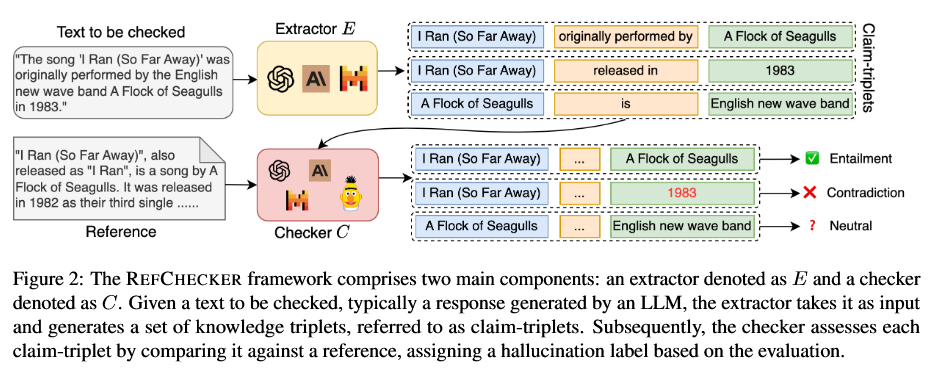
幻觉定义:蕴含、对立、中立
REFCHECKER 框架:
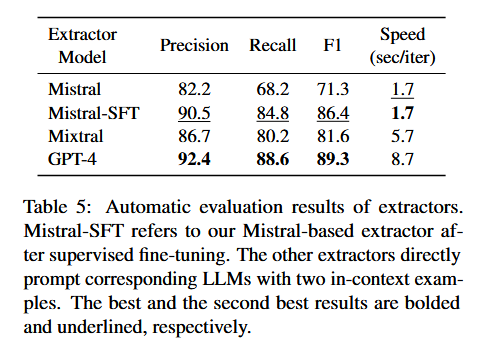
Extractor:GPT4、Mixtral 8x7B 知识蒸馏到Mistral 7B(10k 监督微调)
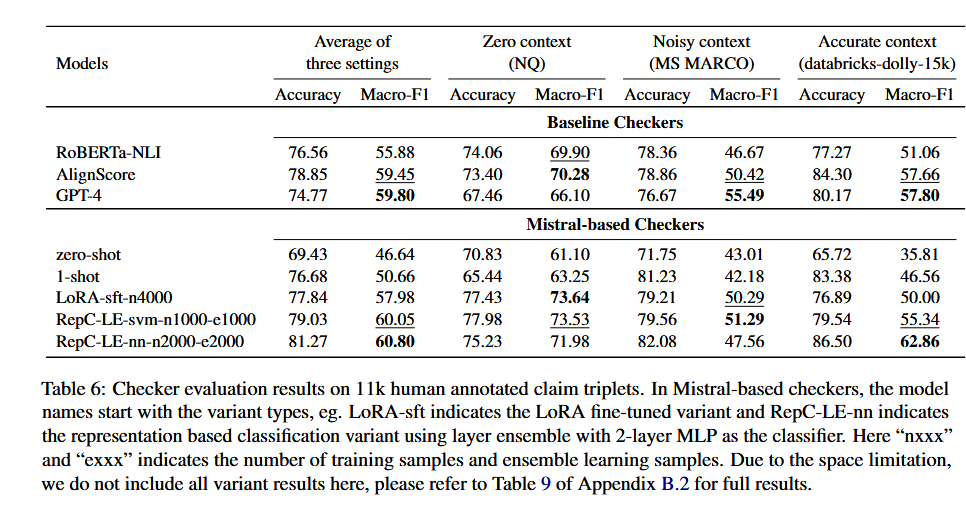
Checker:
- GPT4
- NLI:AlignScore、RoBERTa-NLI
- Mistral 7B
- LoRA-sft
- 基于单层或全部层的表征分类:SVM、2 层 MLP、NCA 后 KNN
聚合:可自定义
数据集构建:
- ZC: NaturalQuestions (NQ),GPT-3.5-Turbo 过滤掉模型拒绝回答或参考源质量低的
- MS MARCO: 选择包含问题答案的黄金段落已被注释的示例
- databricks-dolly15k4: closed_qa, information_extraction and summarization
Experiments
- 检测的细粒度:KNOWHALBENCH
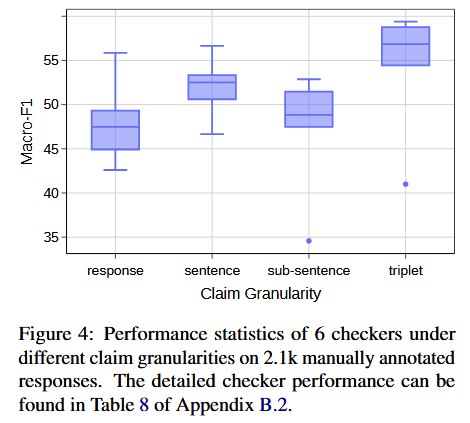
- SelfCheckGPT
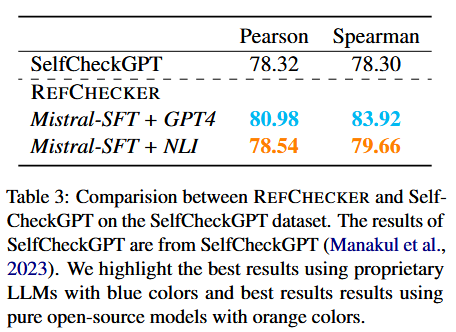
- KNOWHALBENCH 和其他主流方法比较
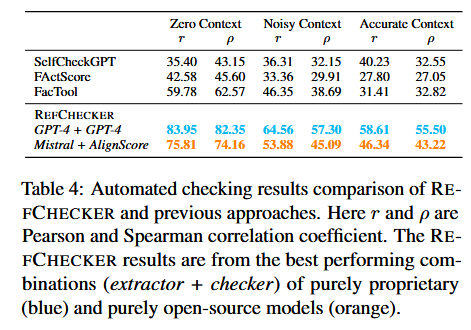
消融实验:
提取器:
检查器:
Future Work
Limitations:
- 三元组依然无法充分涵盖复杂的语义,且由于推理和有限的上下文窗口而导致的高级幻觉形式很难用偏向于局部上下文的三元组来管理
- 各种数据格式(表格、代码、数学等)和特定领域(商业、医疗、法律等)。
- 基于模型的检查器可能会表现出对内部知识的偏见,错误地将中立的声明声明为蕴涵或矛盾,需要我们将某种形式的“知识源控制”注入 LLM
- 在实际部署案例中,用户要求更强的可定制性(例如,他们希望将 REFCHECKER 与自己的数据库一起使用以进行引用检索)和改进速度