白盒检测、浙大、华为、未开源
Motivation
一个关键的挑战 幻觉问题 仍有待解决。
尽管之前做出了努力,但我们认为白盒幻觉检测并没有得到太多研究。白盒检测设置既可以使开源 LLM 社区(例如 LLaMA 或 Mistral)受益,并促使LLM所有者在当前的API形式上提供额外服务。与 black-box 设置相反,white-box 设置可能会利用 transformer 中的完整 token 概率矩阵和 embedding 层。在这项工作中,我们深入研究了这种白盒设置,并证明这些内部信息可能对检测幻觉有很大帮助。
现有的幻觉检测方法大多在 token 级别进行幻觉检测。然而,当模型在输出 token 的同时丢失了大量内部信息时,无疑大大增加了幻觉检测的难度。
Conclusion
本文提出了一种名为 EGH 的白盒幻觉检测方法,该方法利用模型的内部嵌入和梯度来确定幻觉。EGH 基于以下假设:在幻觉产生过程中,模型倾向于在不直接考虑输入问题的情况下生成响应。该模型对输入问题的理解代表了幻觉的程度。我们设计了条件和非条件输入,并利用泰勒展开方法来证明嵌入和梯度特征可以表示这种程度。EGH 在 HaluEval、SelfCheckGPT 和 HADES 等幻觉检测数据集上取得了最先进的结果,验证了我们方法的有效性。
Related Work
幻觉分类:
- 内部幻觉(和 input 冲突)和外部幻觉(和 input 无关)(Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38.)
- input 冲突、上下文冲突、事实冲突(Siren’s song in the ai ocean: A survey on hallucination in large language models. arXiv preprint arXiv:2309.01219.)
幻觉不可避免( Calibrated language models must hallucinate. arXiv preprint arXiv:2311.14648、Unfamiliar finetuning examples control how language models hallucinate. arXiv preprint arXiv:2403.05612.、Hallucination is inevitable: An innate limitation of large language models. arXiv preprint arXiv:2401.11817.)
检测方法:
- 数值指标:ROUGE、PARENT
- 基于模型检测:FACTSCORE、基于条件 LM 和非条件 LM 的 loss(Controlled hallucinations: Learning to generate faithfully from noisy data. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 864–870.)
- 多次问询(Self-contradictory hallucinations of large language models: Evaluation, detection and mitigation. arXiv preprint arXiv:2305.15852.)利用 LLM 评估器检测被测 LLM 是否存在上下文不一致
Method
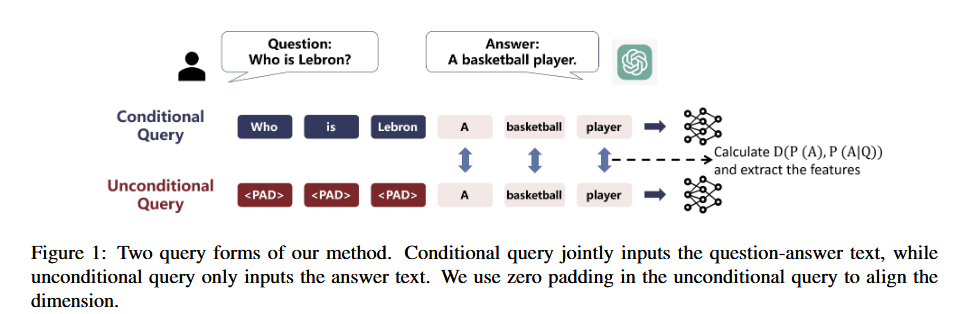
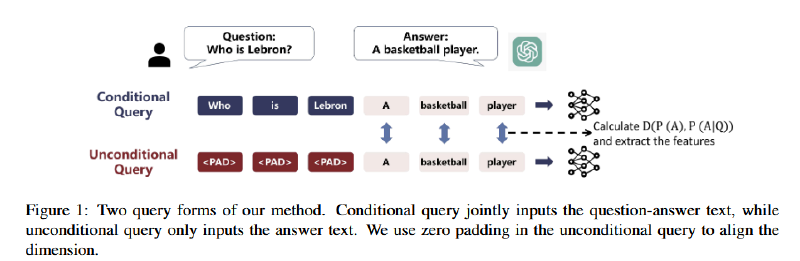
- QA task 中,$ Q = {Q_1, Q_2, …, Q_m}, A = {A_1, A_2, …, A_n} $m 和 n 代表 token 数量。任务是对 A 分类并获得 $ y_{hal} \in {0, 1} $
- 方法基于这样一个假设,即在产生幻觉时,模型往往会从源文本 Q 中吸收较少的信息,并且输出与源文本无关。因此,模型访问 Q 的程度在一定程度上可以代表幻觉的程度
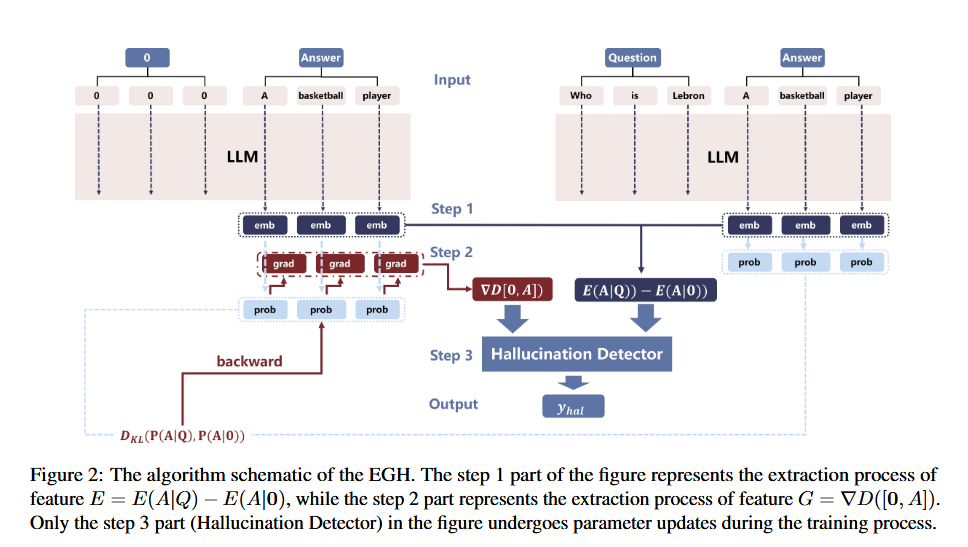
- 分别将 [Q, A] 和 [0, A] 喂给 LLM,其中 0-padding 部分在前向传递时进行 mask,相当于直接输入 A。测量两次的概率分布并计算差异 D([Q, A]),D()可微分,可以是 KL 散度、交叉熵等。D 越大代表 A 的输出越依赖 Q,即幻觉概率越小
$ D([Q, A]) = \text{Difference}(P(A|Q), P(A|0)) $
D 可微分,一阶泰勒展开:
$ D([Q, A]) = D([0, A]) + [\nabla D([0, A])]^{T} ([Q, A] - [0, A]) + R_1([Q, A]) $
D([0, A])是定值,R1 高阶项计算复杂忽略不考虑
- [Q, A] - [0, A]:token 相减没有意义,因此考虑 embedding 层。E = E(A|Q) - E(A|0)是两个 input 模式下的 A 的 embedding 层向量的差。最终取了最后一层隐藏层作为 embedding,E 的形状为 [n, h]
- $ \nabla D([0, A]) $:计算 0 填充前后的 A_i 的 KL 散度之和$ D([Q,A]) = \sum_{i=1}^{n} D_{KL}[P(A_i|Q) || P(A_i|0)] $,再由反向传播获得到对应 embedding 层的梯度,即$ G = \nabla D([0, A]) $
$ y_{hal} = f(\lambda E + (1 - \lambda)G) $,E 和 G 进行加权并平均池化为长度为 h 的向量,f 取三层的 MLP 并训练来实现二分类。
Experiments
实验中$ \lambda $取 0.8,三层 MLP,前两层将维度缩放至一半,最后一层转换成概率,ReLU 作为激活函数。
分别在 HaluEval、SelfCheckGPT、HADES 三个 benchmark 上实验并于对应 baseline 和其他主流方法比较
- HaluEval
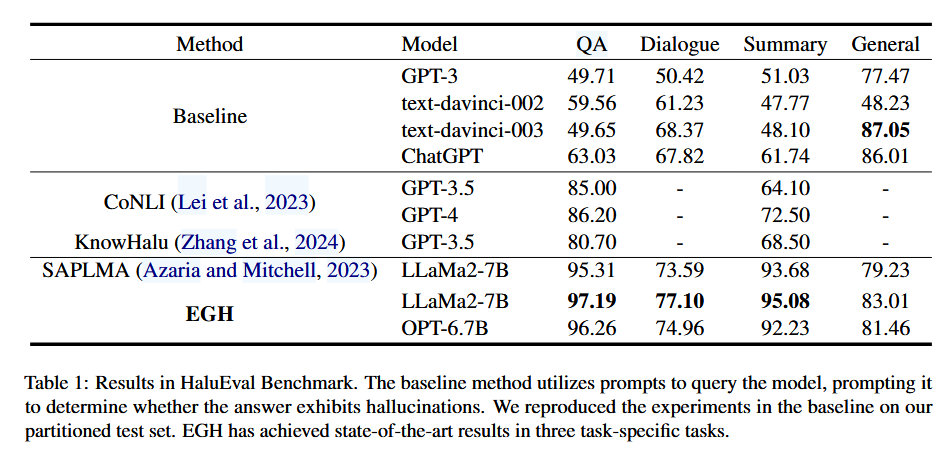
选用 Llama-2-7B 和 OPT-6.7B 作为幻觉生成模型;其余方法在对应模型上采取直接问询的方式检测
相比于 baseline 在除 General 之外(原因可能是 label 分布不平衡)提示显著,相比于另一个白盒检测方法 SAPLMA 提升 2-3%,SOTA。
- SelfCheckGPT
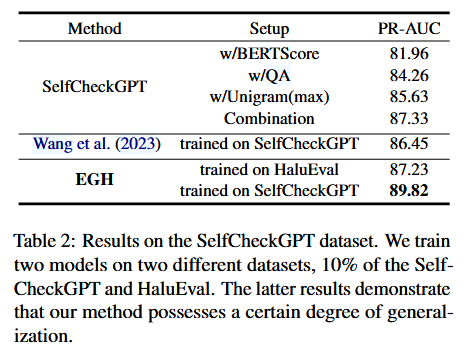
baseline 部分的数据直接使用原论文中的,还和 Wang 等人论文中的结果进行了比较。在 SelfCheck-GPT 数据集的 10%上继续训练则会继续提升 2-3%。证明方法表现出一定程度的泛化性,适用于各种任务和数据集
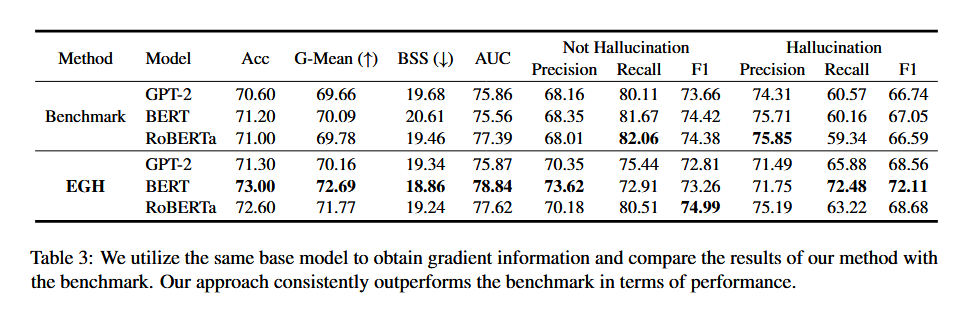
- HADES
选用和 baseline 中相同的模型和设置,用于验证 EGH 在 BERT 等传统模型上也能用
消融实验:
- $ \lambda $选择 0 0.2 0.5 0.8 1,由于 QA 和摘要任务的准确性更高,使消融效果不那么明显,因此对对话任务进行了实验。0.8 时准确率更高,证明两特征都有作用且 embedding 作用更大
- D()的选取:EGH(该研究方法)、 KL 散度和交叉熵
- hal 和 non-hal 时的 KL 散度和交叉熵的概率分布证明相关性
- 逻辑回归+KL 和 CE 作为二维特征,证明直接利用概率、KL 散度、交叉熵等特征无法有效地模拟幻觉
Future Work
Limit:需要利用梯度信息并且需要梯度反向传播,增加了该方法的时间和空间复杂性。在时间方面,需要两个输入,尽管可以通过批量输入来缓解。在空间方面,需要梯度计算和额外的空间来存储信息。