动手学深度学习v2
课程链接:https://courses.d2l.ai/zh-v2/
词嵌入 word2vec
-
词向量:单词的特征向量
-
词嵌入:单词映射到实向量
-
独热向量:容易构造,但不能表示出不同词之间的相似度
-
自监督的 word2vec:将每个词映射到一个固定长度的向量,能更好地表达不同词之间的相似性和类比关系
- 跳元模型 Skip-Gram
- 连续词袋 CBOW
BERT 预训练
BERT:
- 基于微调的 NLP,新任务只需增加一个简单的输出层
- 只有编码器的 Transformer
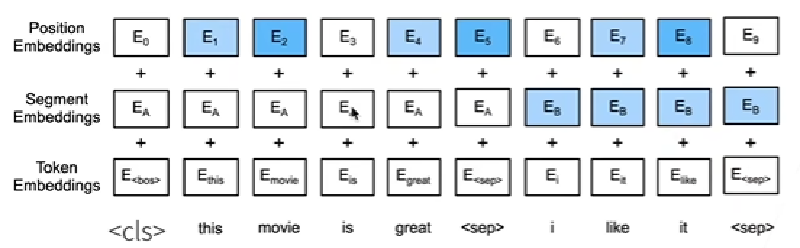
输入表示
- 由于缺少了解码器,目标句子没地方输入,于是将源句子和目标句子拼接后放入编码器
- 以
开头,通过分隔符 将句子分割 - 段嵌入:将不同的句子区分
- 位置嵌入:位置编码可学习
|
|
|
|
|
|
预训练任务
掩蔽语言模型
- Transformer 的编码器是双向的,但标准语言模型做预测时要求单向
- 预训练任务中随机选择 15% 的词元替换成
- 微调时
不会出现,因此选择输入中替换: - 80%:换成
- 10%:换成随机词元
- 10%:保持原有词元
- 80%:换成
|
|
下一句子预测
- 预测一个句子对中的两句子是否相邻
- 训练样本:50%选择相邻句子对、50%随机句子对
- 将
对应的输出放到一个全连接层中做预测
|
|
整合代码
|
|
用于预训练 BERT 的数据集
|
|
|
|
为预训练任务定义辅助函数
生成下一句预测任务的数据
|
|
生成遮蔽语言模型任务的数据
|
|
|
|
将文本转换为预训练数据集
|
|
|
|
|
|
|
|
预训练 BERT
14.10. 预训练BERT — 动手学深度学习 2.0.0 documentation (d2l.ai)
情感分析
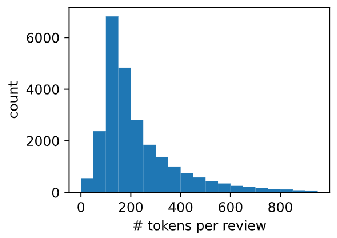
数据集
|
|
|
|
使用循环神经网络
序列级和词元级使用微调 BERT
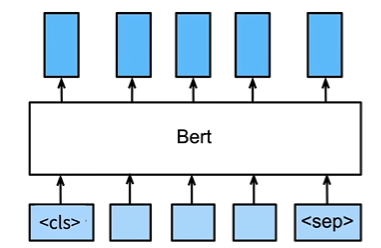
- BERT 会对每一个词元返回抽取了上下文信息的特征向量
- 即使下游的任务各有不同,微调时只需要加输出层,并使用相应的 BERT 特征
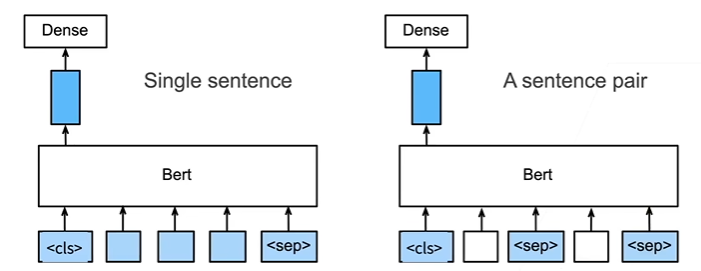
单文本分类
- 将
对应的向量输入到全连接层分类
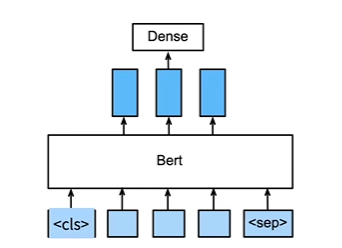
命名实体识别
- 识别一个词元是否是命名实体,如人名、机构、位置
- 将非特殊词元放进全连接分类
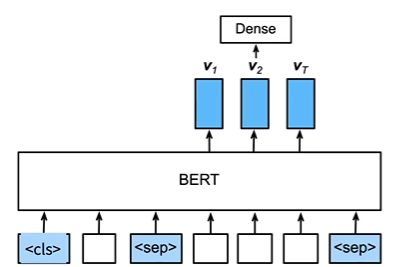
问题回答
- 给定问题、描述文字(
分隔),找出片段作为回答 - 对片段中的每个词元,预测其是否是回答的开头或结束
自然语言推理数据集
15.4. 自然语言推断与数据集 — 动手学深度学习 2.0.0 documentation (d2l.ai)
|
|
|
|
|
|
|
|
|
|
自然语言推断:微调 BERT
|
|
加载预训练的 BERT
|
|
|
|
微调 BERT 的数据集
|
|
微调 BERT
|
|
微调 tricks
- 处理长文本:
分为截断法和层级法
截断法:头、尾、头+尾
层级法:分成 k 个片段,分别喂给 BERT 后将表示向量通过均值池化等方式来组合所有分数的表示
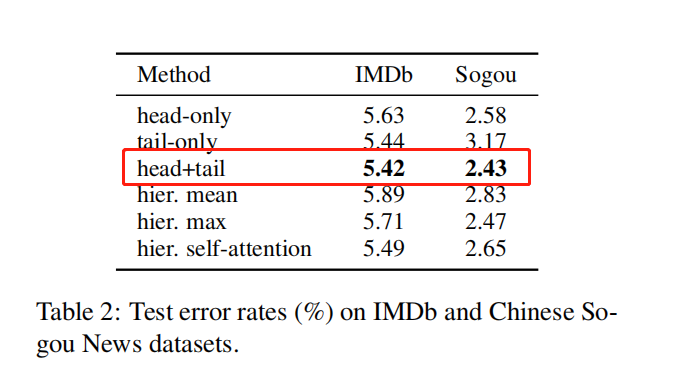
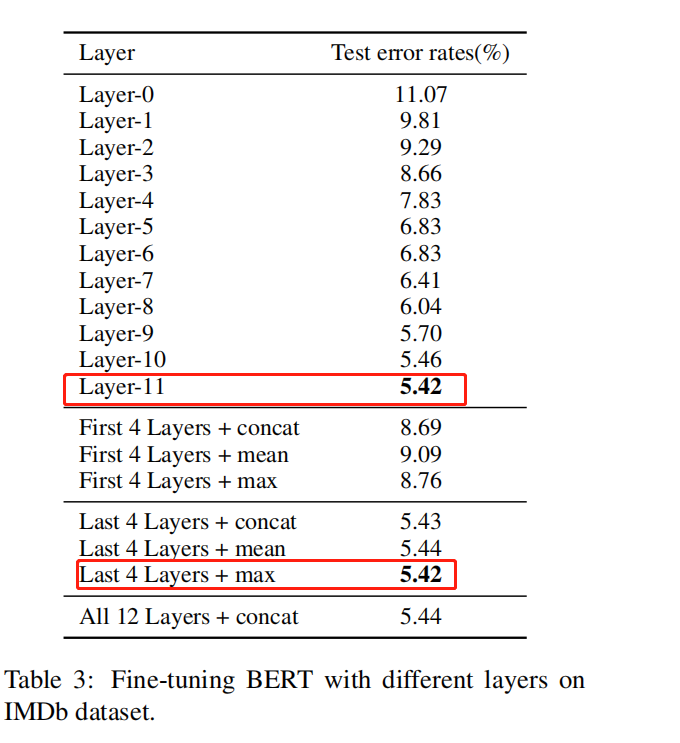
- 不同层的特征:最后一层表征效果最好,最后四层进行最大值池化效果最好
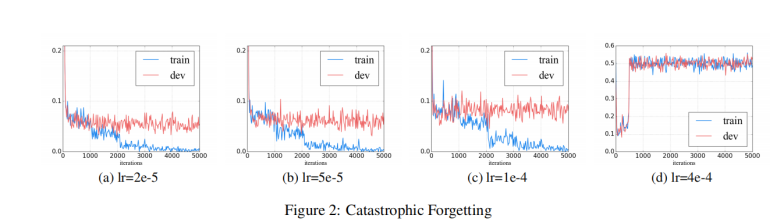
- 灾难性遗忘
Catastrophic forgetting (灾难性遗忘)通常是迁移学习中的常见诟病,这意味着在学习新知识的过程中预先训练的知识会被遗忘。
2e-5 才能克服灾难性遗忘问题,预训练模型训练不能收敛时要多检查超参数设置是否有问题
- ITPT:继续预训练
Bert是在通用的语料上进行预训练的,如果要在特定领域应用文本分类,数据分布一定是有一些差距的。这时候可以考虑进行深度预训练。
Within-task pre-training:Bert在训练语料上进行预训练
In-domain pre-training:在同一领域上的语料进行预训练
Cross-domain pre-training:在不同领域上的语料进行预训练
- BERT 在 Adam 中移除了偏差纠正,在微调时尽量使用完整版 Adam
|
|
- 尽量训练 3 个以上 epoch
- 可以固定住底层或将顶层随机初始化