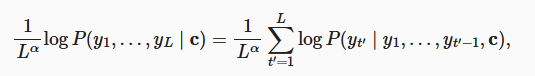动手学深度学习v2
课程链接:https://courses.d2l.ai/zh-v2/
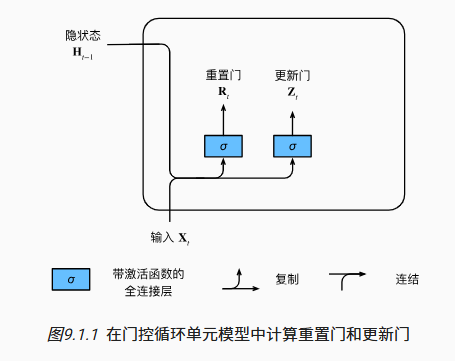
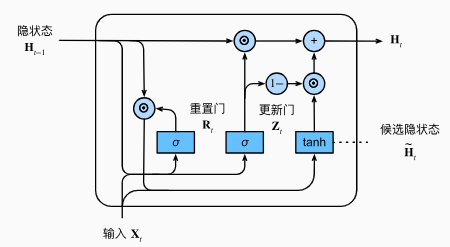
门控循环单元 GRU
主要思想
- 不是每一个观察值都同等重要
- 更新门:关注
- 重置门:遗忘
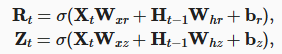
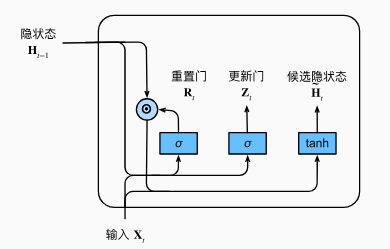
候选隐状态
![]()
$ R_t $中的值保持在 [0, 1] 范围内,代表了对过去状态的记忆程度,接近于 0 时会将先前的状态大幅度遗忘
隐状态
![]()
$ Z_t $趋于 1 时,等于直接照搬过去的状态,不考虑这一轮的$ X_t $
$ Z_t $趋于 0 时,只考虑目前的状态,等价回 RNN
$ R_t $控制保留过去多少状态,$ Z_t $控制保留这一轮多少状态
代码实现
从零实现
|
|
初始化参数
|
|
定义模型
|
|
|
|
训练与预测
|
|
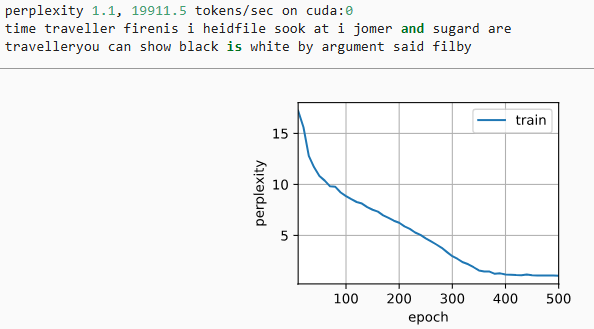
简洁实现
|
|
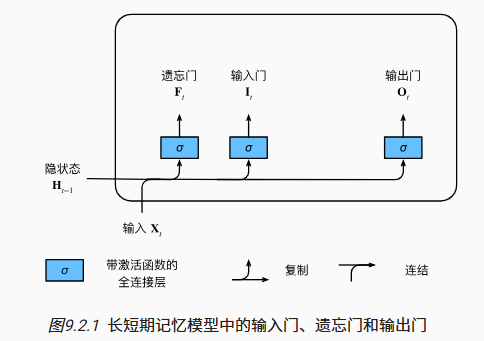
长短期记忆网络 LSTM
主要思想
- 忘记门
- 输入门
- 输出门
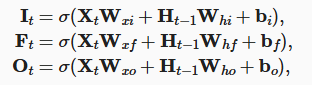
候选记忆元
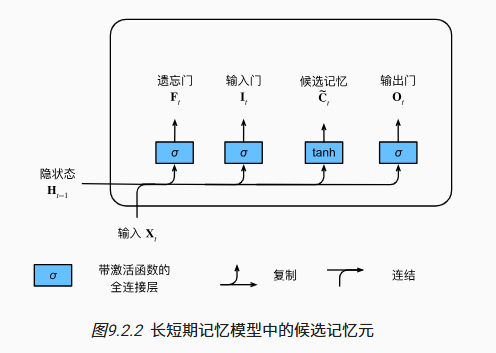
![]()
记忆元
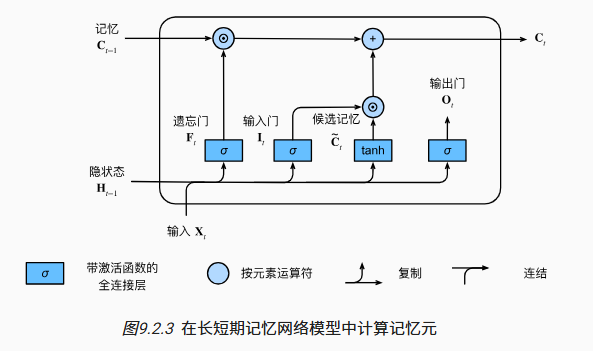
![]()
$ F_t $: 是否遗忘该轮$ X_t $
$ I_t $: 是否记忆该轮$ X_t $
和 GRU 不同的是,LSTM 中的 F_t 和 I_t 是独立的,可以既保留过去记忆又保留当前记忆
隐状态
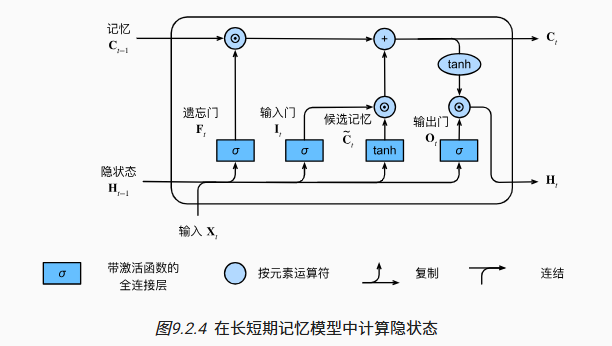
![]()
将 C_t 的值限制在 (-1, 1)中,并使用 O_t 控制输出
代码实现
|
|
初始化参数
|
|
定义模型
|
|
训练和预测
|
|
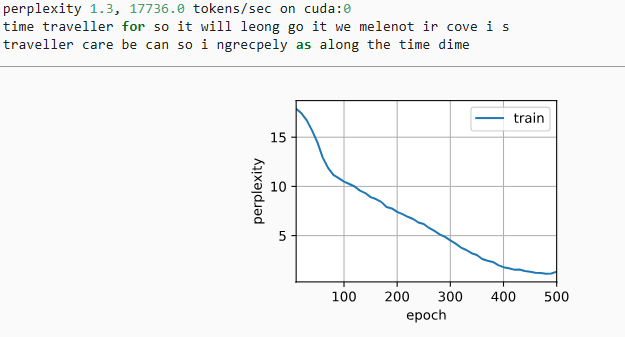
简洁实现
|
|
深度循环神经网络
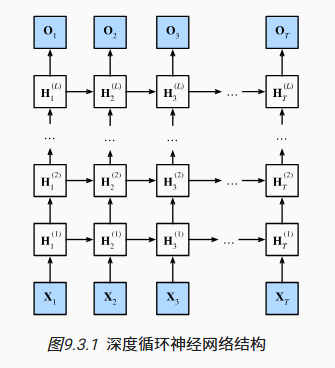
![]()
![]()
|
|
|
|
双向循环神经网络
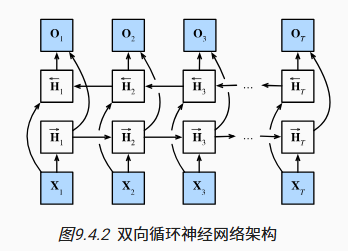
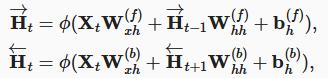
![]()
双向 RNN 主要用来对句子进行特征提取或填空,通常不用来推理
|
|
机器翻译与数据集
|
|
|
|
|
|
|
|
|
|
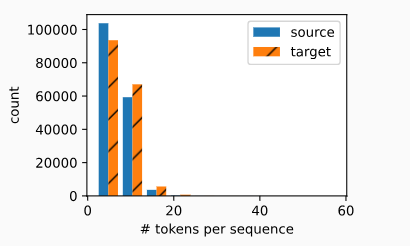
|
|
|
|
|
|
训练模型
|
|
|
|
编码器和解码器
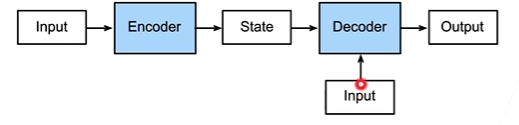
|
|
|
|
|
|
序列到序列学习 seq2seq
主要思想
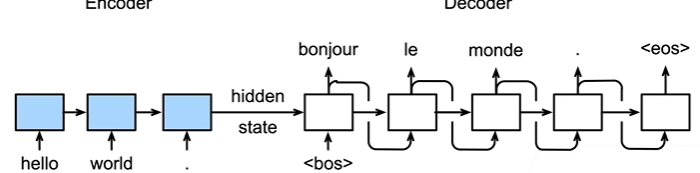
- 编码器是一个 RNN,读取输入句子
- 可以是双向 RNN
- 解码器是另一个 RNN,接收 encoder 的 state 来输出
- 编码器不需要输出,其最后时间步的隐状态作为解码器的初始隐状态
训练: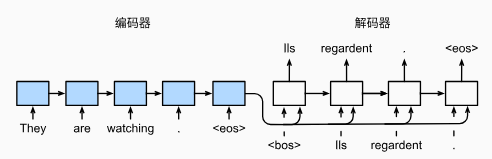
预测: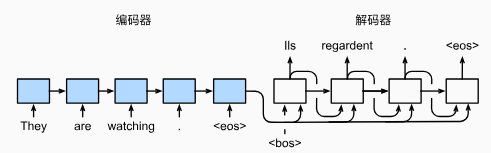
- 训练时 decoder 会使用目标句子作为输入,而预测时则只能使用上一个预测出的词作为输入
预测序列的评估
BLEU(bilingual evaluation understudy)
$ p_n $是预测所有 n-gram 的精度, 是预测序列与标签序列中匹配的n元语法的数量, 和预测序列中n元语法的数量的比率
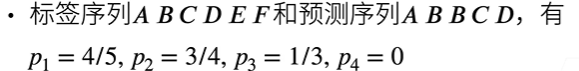
BLEU 定义:
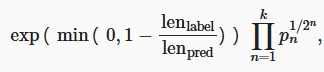
exp 项用来惩罚过短的预测,求和项中的指数使得长匹配具有高权重
代码实现
|
|
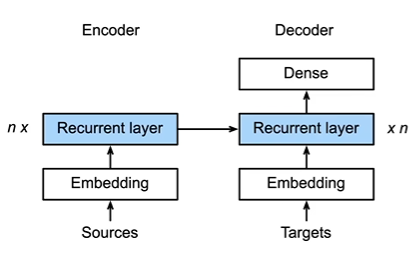
编码器
|
|
|
|
解码器
|
|
损失函数
|
|
|
|
训练
|
|
|
|
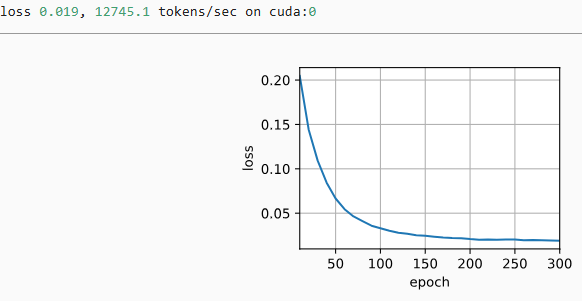
预测
|
|
预测序列的评估
|
|
束搜索
seq2seq 中使用了贪心搜索的策略,即将当前时刻预测概率最大的词输出
但贪心并不一定最优
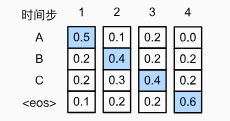
前者(贪心)=0.048,后者=0.054
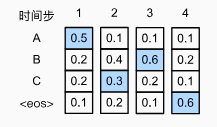
- 穷举搜索:计算所有可能序列的概率,不可能实现
- 束搜索:n 个可选,保存最好的 k 个候选
时间复杂度:O(knT)
句子越长概率越低,为了避免倾向于选过短的句子,在取 log 后乘上 L 项