动手学深度学习v2
课程链接:https://courses.d2l.ai/zh-v2/
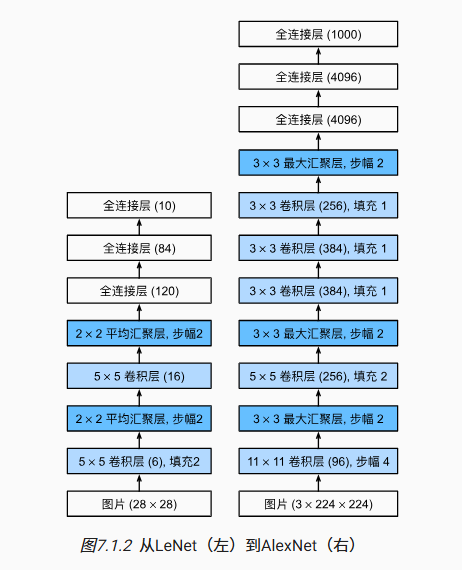
深度卷积神经网络 AlexNet
AlexNet
相比于LeNet:
- 更深更宽
- 激活函数从sigmoid变成ReLU(减缓梯度消失)
- 隐藏全连接层后加入了丢弃层
- 数据增强
代码实现
|
|
使用块的网络 VGG
- 将AlexNet的多层结构替换为VGG块
- VGG: 33卷积核、填充为1(保持高度和宽度)的卷积层,和22汇聚窗口、步幅为2(每个块后的分辨率减半)的最大汇聚层
|
|
VGG-11: 8个卷积层和3个全连接层
原始VGG网络有5个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层。 第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11。
|
|
网络中的网络 NiN
全连接层的问题:卷积层参数较少,但卷积层后的第一个全连接层参数过多
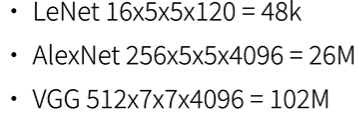
核心思想:
- NiN块:卷积层+2 个 11 卷积层, 11 卷积层前后的 ReLU 对每个像素增加了非线性性
- 模型最后端采用全局平均池化层,来代替 VGG 和 AlexNet 中的全连接层 => 不容易过拟合,更少的参数
|
|
|
|
含并行连结的网络 GoogLeNet
Inception 块
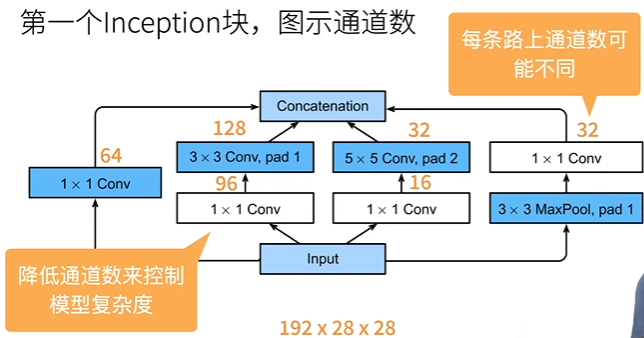
- 输入和输出的宽高相等,但通道数改变
- 白色快用来改变通道数,蓝色块用来抽取信息
- 和 33 或 55 卷积层相比,Inception 块的参数个数更少,计算复杂度更低
- 由后续各种变种 V2、V3、V4
GoogLeNet
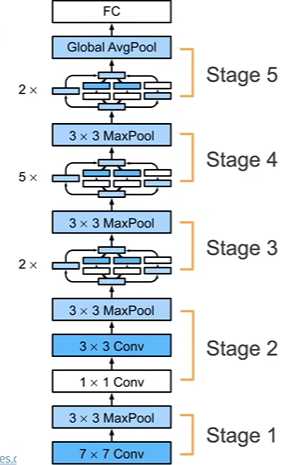
Stage 1 & 2
GoogLeNet 使用了更小的卷积层,最终的宽高更大,从而之后可以使用更深的网络
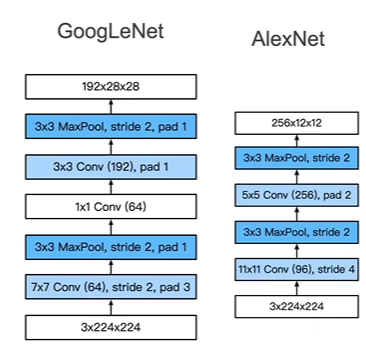
Stage 3
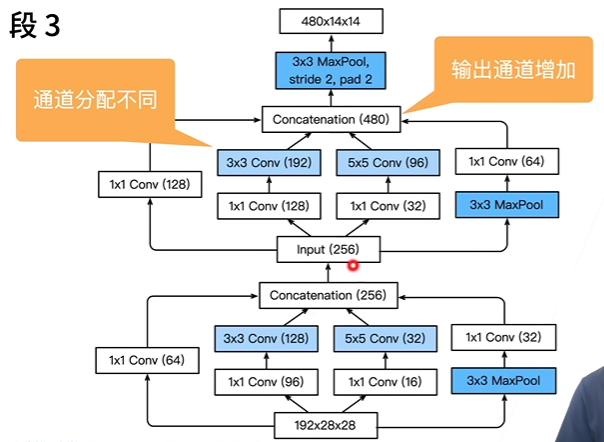
通道分配基本无规律可总结
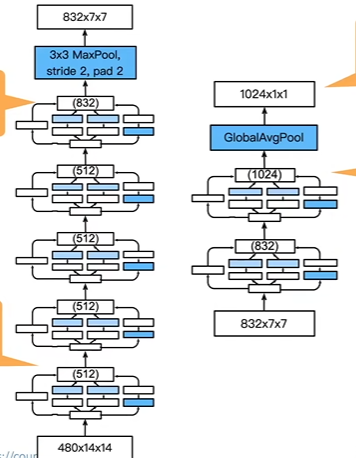
Stage 4 & 5
代码实现
7.4. 含并行连结的网络(GoogLeNet) — 动手学深度学习 2.0.0 documentation
照着网络敲代码
|
|
批量归一化
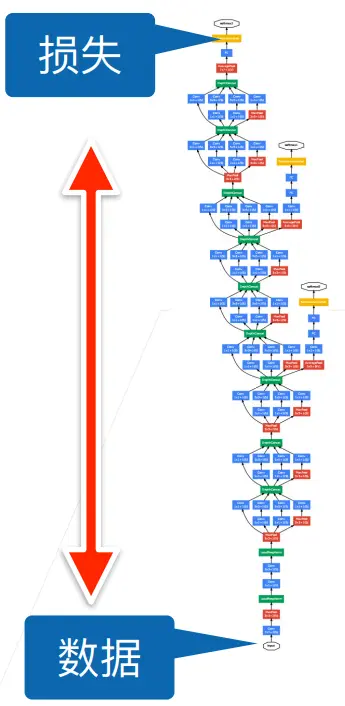
核心思想
- 反向传递时,数据由上至下传递。梯度由于相乘,越靠下梯度越小。因此底层的变化会导致上层的数据跟着变,需要重新学习,导致收敛变慢
- 能否在学习底部的时候尽量避免顶部的变化?
- 变化是因为每层方差和均值不同,考虑将不同层的不同位置的小批量的分布固定
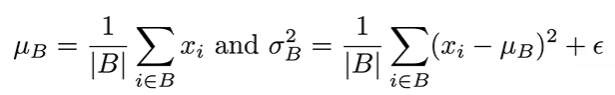 ($ \epsilon $确保$ \sigma_B $不为 0)
($ \epsilon $确保$ \sigma_B $不为 0)
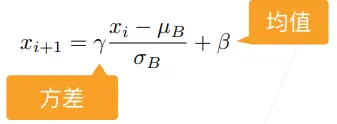
批量归一化层
- 作用在全连接层和卷积层的输出上,激活函数前:批量归一化是线性变化
- 或作用在全连接层和卷积层的输入上
- 对全连接层的作用是在特征维度上,对卷积层的作用在通道维上
- 特别是 1*1 的卷积核,就是将所有的像素当成样本来计算均值和方差,通道维可以看作是卷积层的特征维
作用
- 最初想法:减少内部协变量转移(用今天的数据拟合明天)
- 后续指出:在每个小批量中加入噪音来控制模型复杂度(选取小批量时是随机选取的,因此方差和均值也可看作是随机的)
- 因此没必要和丢弃法 dropout 混合使用
总结:
- 固定小批量中的均值和方差,然后学习出适合的偏移和缩放
- 可以加快收敛速度,但一般不改变模型精度
代码实现
从零实现
|
|
简洁实现
|
|
残差网络 ResNet
由 VGG 更改而来
计算底层梯度时可以直接通过右侧 1*1 卷积层,因此底层也可以得到较大的梯度,这使得 ResNet 可以训练出 1000 层的模型
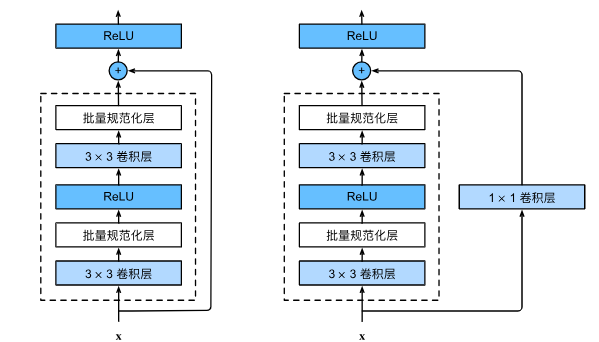
g(x) = f(x) + x
1*1 卷积层调整通道数
|
|
|
|