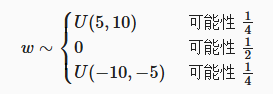1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
print(rgnet)
# Sequential(
# (0): Sequential(
# (block 0): Sequential(
# (0): Linear(in_features=4, out_features=8, bias=True)
# (1): ReLU()
# (2): Linear(in_features=8, out_features=4, bias=True)
# (3): ReLU()
# )
# (block 1): Sequential(
# (0): Linear(in_features=4, out_features=8, bias=True)
# (1): ReLU()
# (2): Linear(in_features=8, out_features=4, bias=True)
# (3): ReLU()
# )
# (block 2): Sequential(
# (0): Linear(in_features=4, out_features=8, bias=True)
# (1): ReLU()
# (2): Linear(in_features=8, out_features=4, bias=True)
# (3): ReLU()
# )
# (block 3): Sequential(
# (0): Linear(in_features=4, out_features=8, bias=True)
# (1): ReLU()
# (2): Linear(in_features=8, out_features=4, bias=True)
# (3): ReLU()
# )
# )
# (1): Linear(in_features=4, out_features=1, bias=True)
# )
# 访问第一个主要的块中、第二个子块的第一层的偏置项
rgnet[0][1][0].bias.data
# tensor([ 0.1999, -0.4073, -0.1200, -0.2033, -0.1573, 0.3546, -0.2141, -0.2483])
|