动手学深度学习v2
课程链接:https://courses.d2l.ai/zh-v2/
注意力提示
主要思想
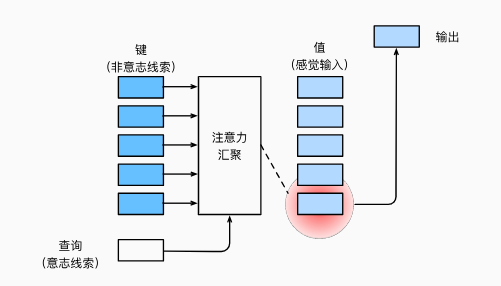
随意线索:主动有意识去观察线索
- 随意线索:查询(query)
- 感觉输入(value)
- 不随意线索(key)
- 注意力池化层/汇聚层
query(value) -> key
非参注意力池化层
平均池化: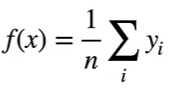
Nadaraya-Watson 核回归: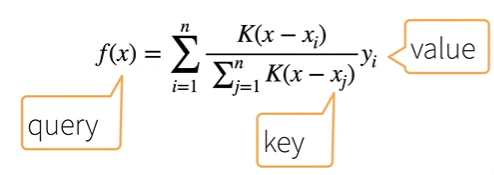
使用高斯核: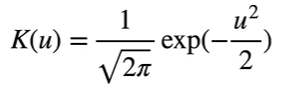
则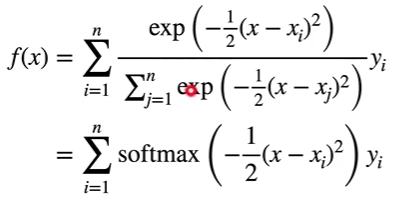
f(x) 可写作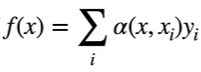 ,其中$ \alpha(x, x_i) $为权重
,其中$ \alpha(x, x_i) $为权重
Nadaraya-Watson 核回归代码实现
|
|
|
|
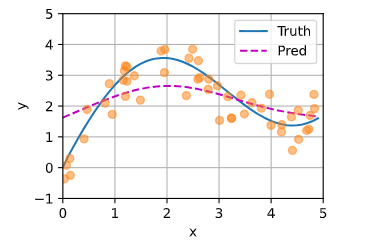
平均汇聚
|
|
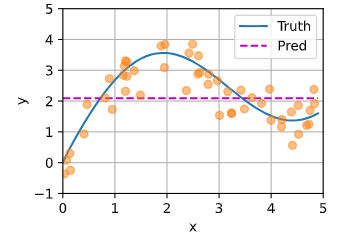
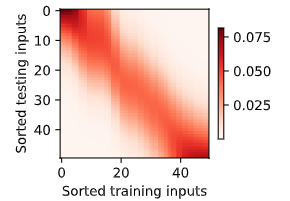
非参数注意力汇聚
|
|
|
|
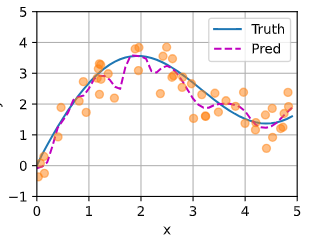
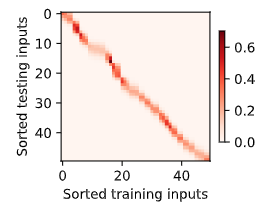
带参数的注意力汇聚
|
|
|
|
|
|
注意力分数
主要思想
注意力分数是 query 和 key 的相似度,softmax 后得到注意力权重
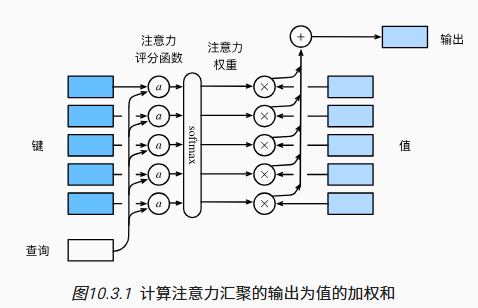

该式中,x_i 就是 key,x 就是 query,函数 a 为-1/2(x - x_i)^2,在经过 softmax 后变成注意力权重,与对应的值相乘后累加得到输出
- 拓展到高维度
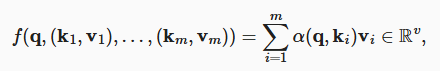
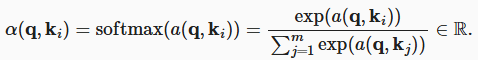
掩蔽 softmax 操作
|
|
|
|
加性注意力 Additive Attention
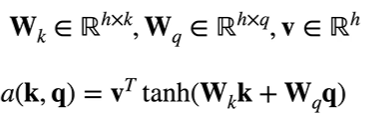
将 key 和 query 乘上自己的可学参数后相加,放入一个隐藏大小为 h 输出大小为 1 的单隐藏层 MLP
|
|
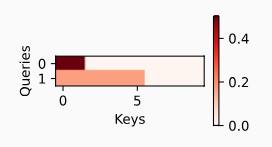
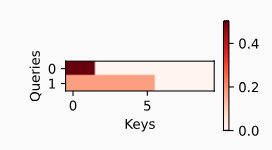
缩放点积注意力 Scaled Dot Product Attention
几何角度解释:两向量方向越接近,点积越大
当 q 和 k 的长度都为 d 时,做内积,然后除以$ \sqrt{d} $来避免对长度敏感
![]()
- 从小批量角度考虑:基于 n 个 query 和 m 个 k-v
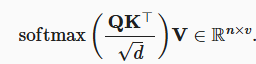
其中 Q(n, d), K(m, d), V(m, v)
|
|
注意力机制的 seq2seq
思路
机器翻译中,每个生成的词可能相关于源句子中不同的词
在翻译时希望将注意力关注在源句子中对应的部分
传统 seq2seq 会将 RNN 中最后一个 state 作为解码时的初始状态
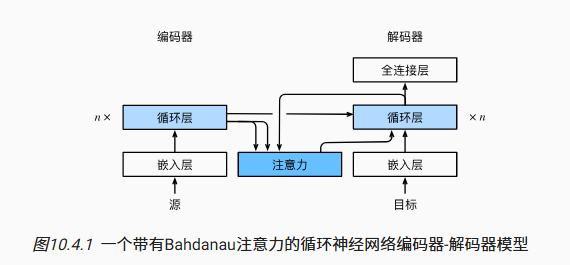
源句子中的每个词都会作为一个 key-value 放入 attention 中
query 则是去源句中对翻译的上一个词对应部分的附近进行查找,即把解码器的输出作为 query
Bahdanau 注意力
|
|
注意力解码器
编码器不变,因为 attention 只作用在 decoder 上
|
|
|
|
|
|
训练
|
|
|
|
|
|
自注意力和位置编码
自注意力
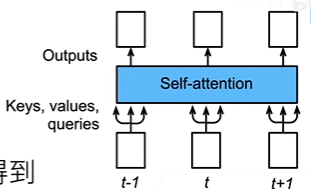
将 x_i 作为 query,所有 (x, x) 作为 key-value 对序列抽取特征得到 y_i
![]()
比较 CNN、RNN、Self-attention
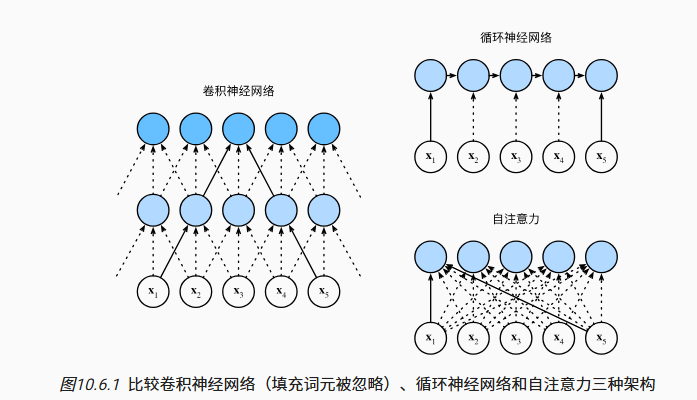
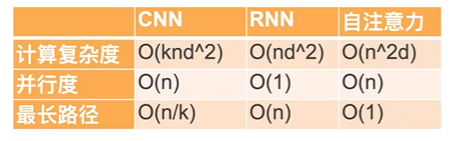
k: kernel 大小
n: 序列长度
d: 输入输出通道数
自注意力机制适合用于长文本,但这也使得计算量非常大
位置编码
- 于 CNN/RNN 不同,自注意力没有记录位置信息
- 位置编码将位置信息注入到输入中

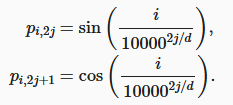
|
|
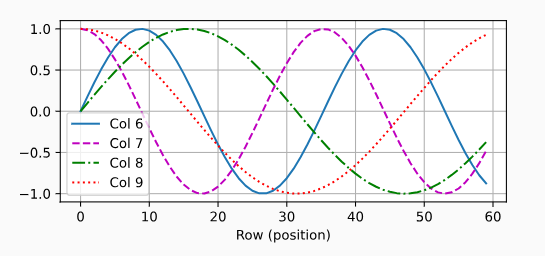
绝对位置信息
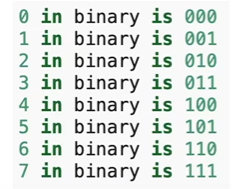
计算机使用二进制编码,越低位次变化的频率越大(例如最低位总是 01 交替)
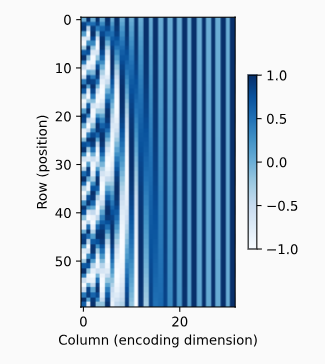
相对位置信息
![]()
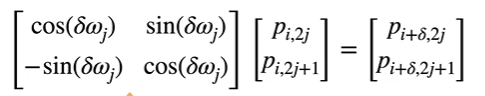
可看出不管 (p_i, p_{i+d}) 在任何位置,其$ \omega_j $的值都相同
$ \omega $因此可以学到不同词之间的相对位置
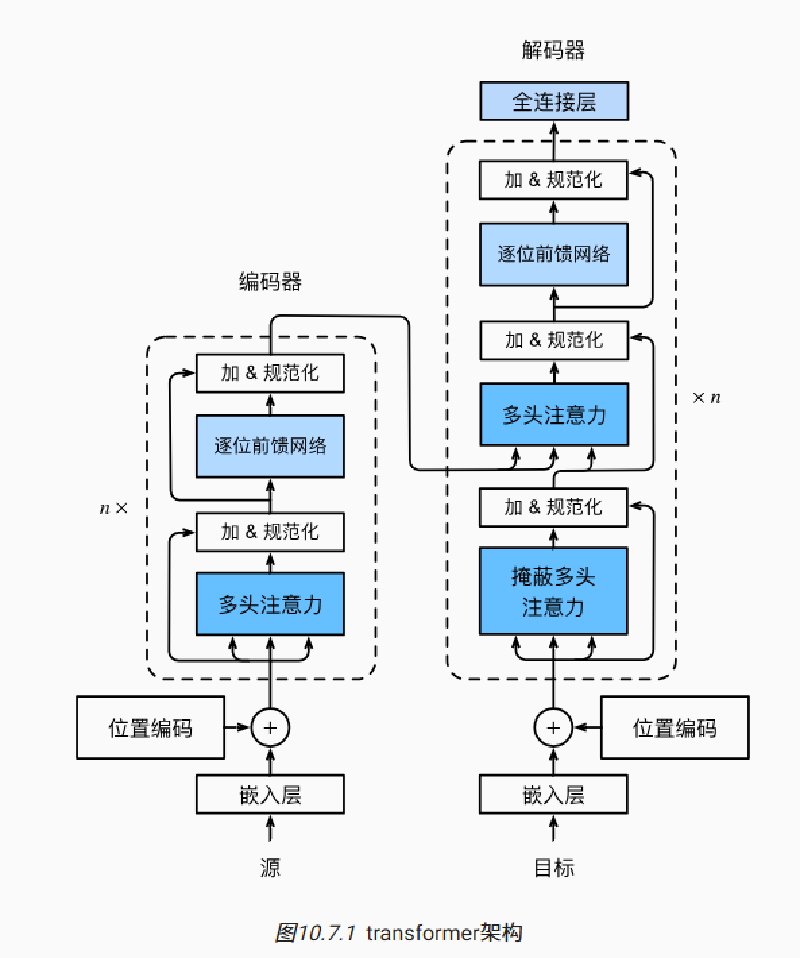
Transformer
- 相比于 seq2seq,Transformer 没有使用 RNN,是纯基于注意力
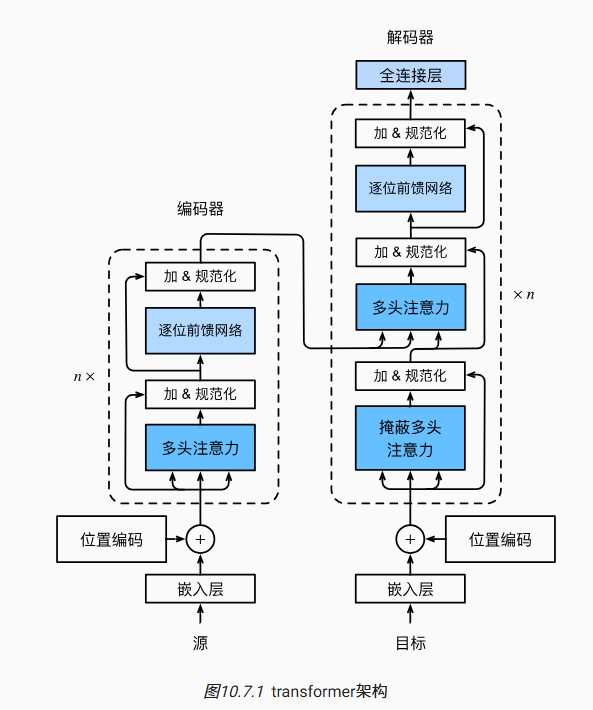
多头注意力
思想
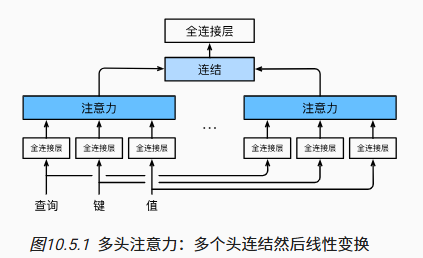
- 输入的 q、k、v:
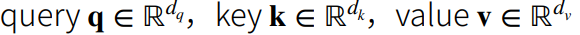
- 头 i 的可学习参数(全连接层):
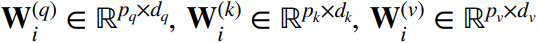
- 头 i 的输出(注意力层):
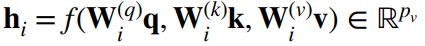
- 输出的可学习参数(顶部全连接层):
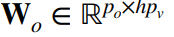
- 多头注意力的输出:
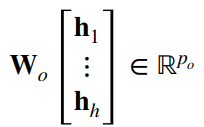
有掩码的多头注意力
- attention 中没有时间先后的概念。这在编码器中适用,但在解码器中,对一个元素输出时不应该考虑该元素之后的元素
- 通过掩码实现:计算 x_i 的输出时,假设当前序列长度为 i,计算 softmax 时后续序列无权重
代码实现
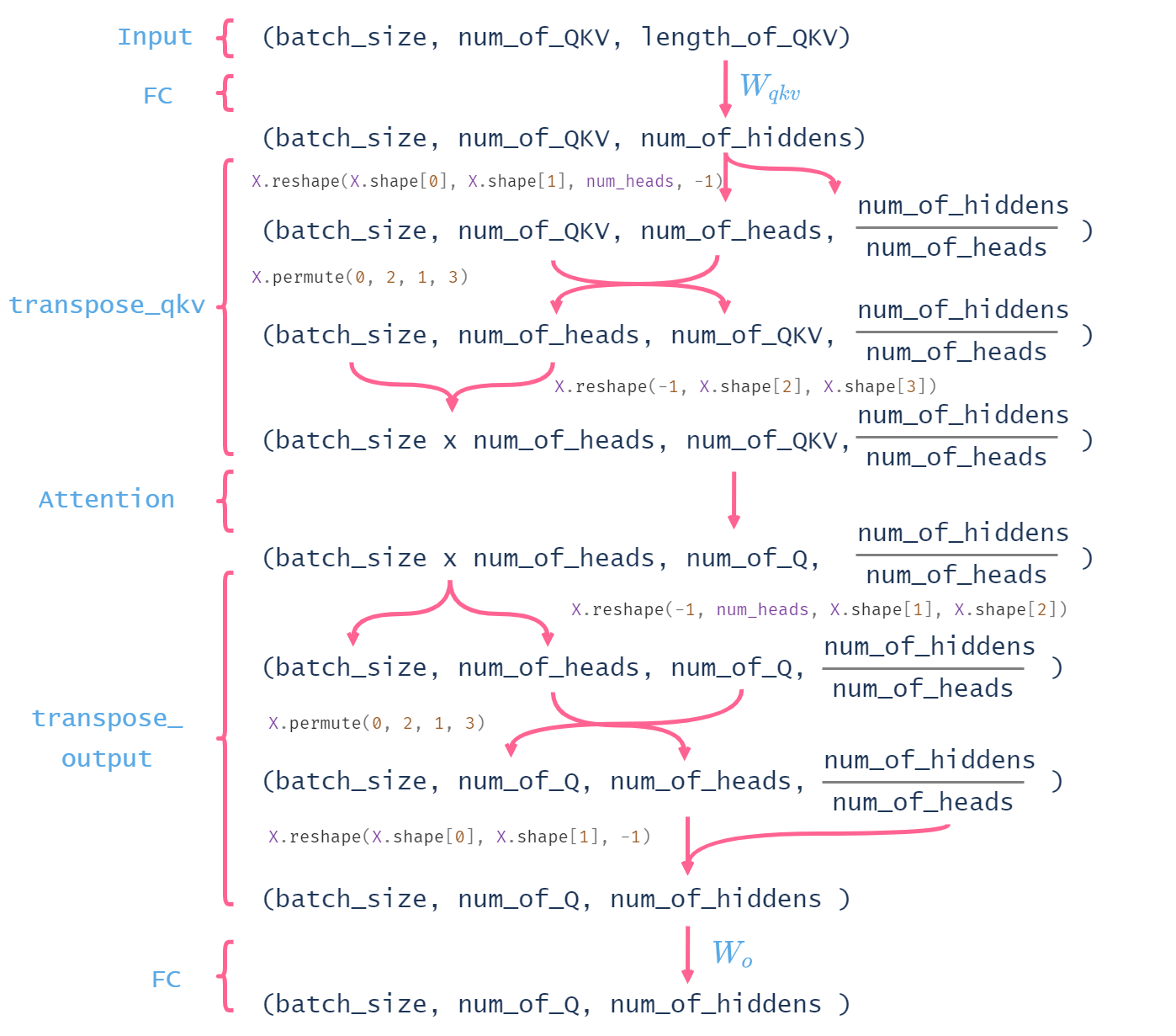
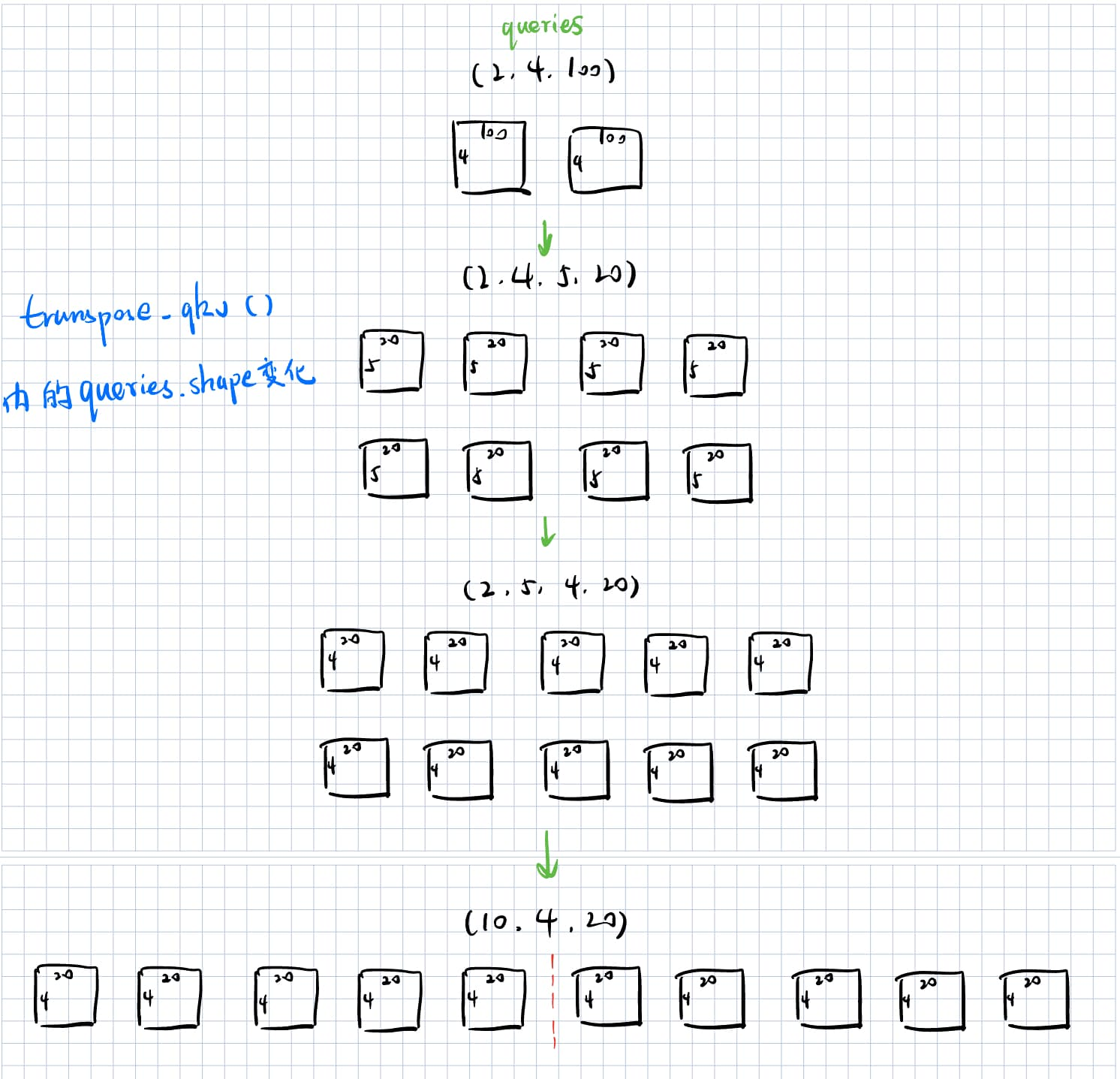
|
|
|
|
|
|
基于位置的前馈网络
- 两个全连接层,等价于两层核窗口为 1 的一维卷积层
- 形状由(bn, d)变换成(bn, d),再变化回(b, n, d)
|
|
|
|
|
|
残差连接和层归一化
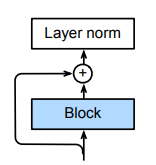 图中 Block 可以是多头注意力、前馈网络等,残差连接后进行归一化
图中 Block 可以是多头注意力、前馈网络等,残差连接后进行归一化
- 在归一化时要进行层归一化而不是批量归一化,层归一化操作的数据归属于一个序列
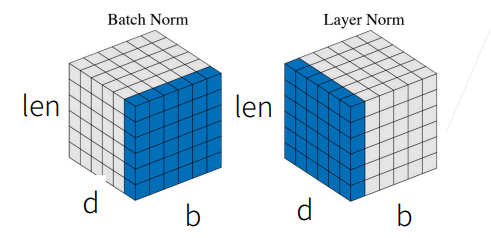
图中沿 b 维度是一个个 batch,沿 d 是序列的特征向量,因此垂直于 b 切开刚好是一个个序列
|
|
编码器
|
|
注:Transformer编码器中的任何层都不会改变其输入的形状
|
|
解码器
编码器输出的向量 y_1, … , y_n 作为解码器中第 i 个 Transformer 块中多头注意力的 key 和 value,query 取自目标序列
这使得编码器和解码器中的块的个数和输出维度相同
|
|
|
|
训练
|
|
预测
预测第 t+1 个输出时,前 t 个预测值作为 key 和 value,第 t 个预测值作为 query