动手学深度学习v2
课程链接:https://courses.d2l.ai/zh-v2/
序列模型
思路
- 在时间 t 观察到$ x_t $,得到 T 个不独立的随机变量
![]()
![]()
- 自回归模型:对见过的数据建模
![]()
- 马尔可夫模型:只和过去$ \tau $个数据点有关
![]()
用 MLP 即可建模
- 潜变量模型
引入潜变量$ h_t $表示过去的信息![]()
![]()
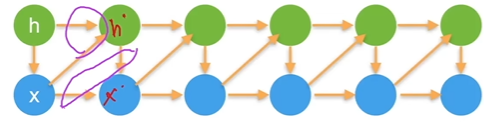
这使得 x 和 h 只与两个变量相关,方便建模
代码
|
|
|
|
|
|
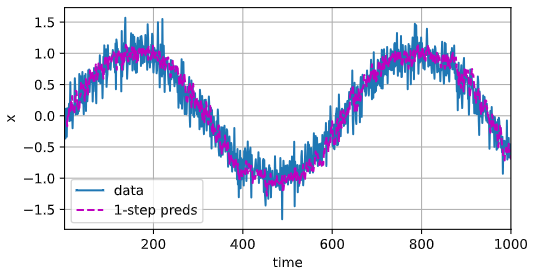
单步预测效果较好
|
|
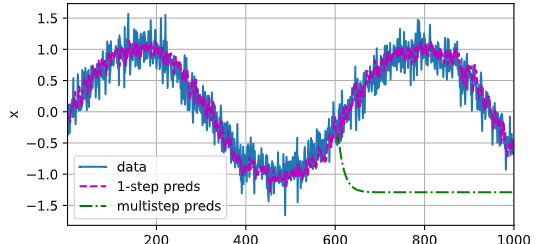
604 之后如果使用自己的预测数据来继续预测,由于错误的累积,效果不好(绿线)
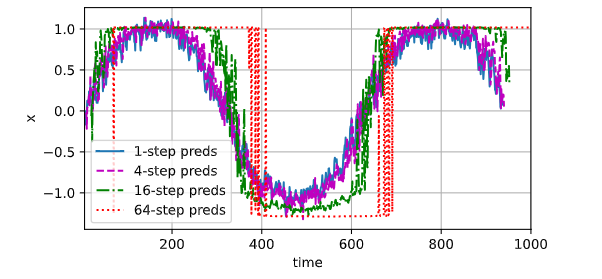
已知 4 个点,分别预测未来 1、4、16、64 个点
文本预处理
读取数据集
|
|
|
|
词元化
|
|
词表
构建一个字典,将每个 token 映射到数字索引上
|
|
|
|
功能整合
|
|
语言模型和数据集
语言模型
给定文本序列$ x_1, …x_T $,语言模型目标是估计联合概率$ p(x_1, …, x_T) $
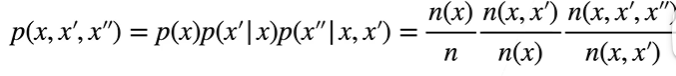
当序列很长时,可使用马尔可夫假设
三元语法:![]()
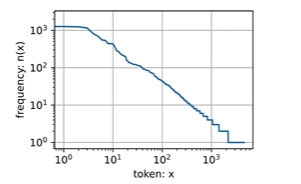
自然语言统计
|
|
|
|
最流行的词通常没有什么意义,被称为停用词
|
|
|
|
|
|
|
|
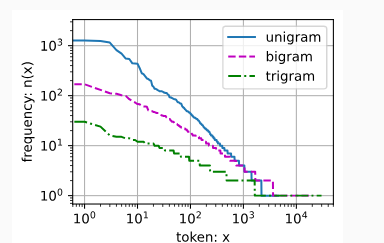
读取长序列数据
随机采样
在 0 到 T-1 之间随机选取起始位置,每 T 个 token 分成一个 batch
这样可以减小切分处序列的影响

|
|
顺序分区
保证两个相邻的小批量中的子序列在原始序列上也是相邻的
|
|
|
|
包装到类:
|
|
|
|
循环神经网络 RNN
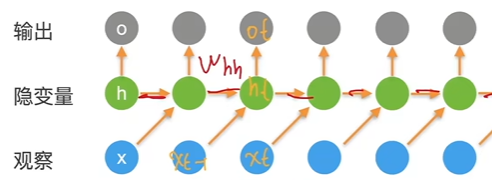
![]()
相比于 MLP 加入了隐变量
困惑度 Perplexity
衡量语言模型好坏时可以用平均交叉熵,平均交叉熵时一个序列中所有的 n 个词元的交叉熵损失的平均值
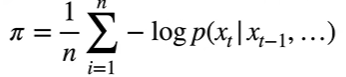
NLP 中使用困惑度来衡量:$ exp(\pi) $
1 表示完美,最坏情况是无穷大
梯度裁剪
T 时间步上的梯度在反向传播时会产生长度为 O(T) 的矩阵乘法链,导致数值不稳定
梯度裁剪来防止梯度爆炸
梯度长度超过$ \theta $时,拖影回长度$ \theta $
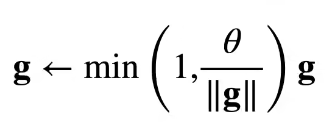
确保了梯度不会大于 1
RNN 应用
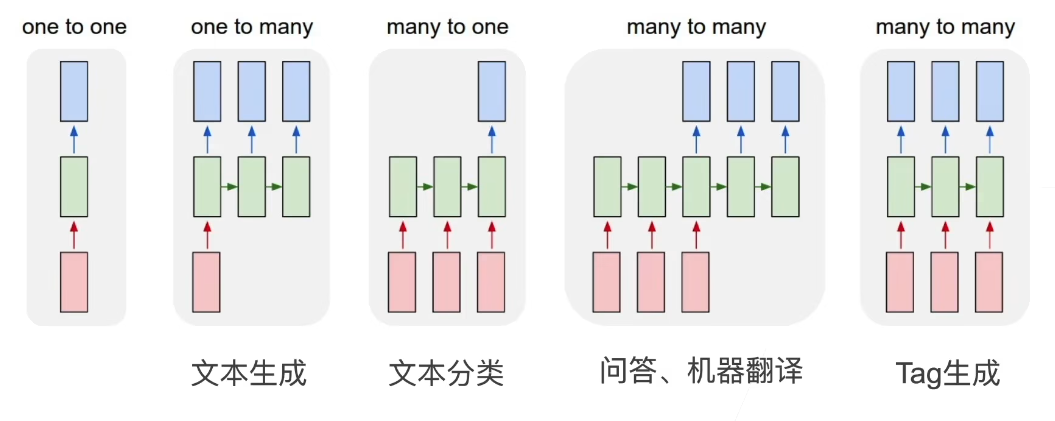
从零实现
|
|
独热编码
通过独热编码可以将词元的数字索引转换成特征向量
|
|
- 采样的小批量数据形状:(批量大小,时间步数)
- 转置输入的维度,以便获得形状为(时间步数,批量大小,词表大小)的输出
- 之所以这样做,是为了方便通过外层的维度,一步一步更新小批量数据的隐状态
- 这样一来 X[i, :, :] 代表 T(i)的状态
|
|
初始化模型参数
|
|
循环神经网络模型
|
|
预测
|
|
梯度裁剪
|
|
训练
|
|
|
|
|
|
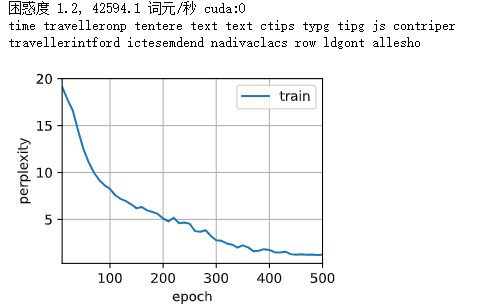
结果
|
|
|
|
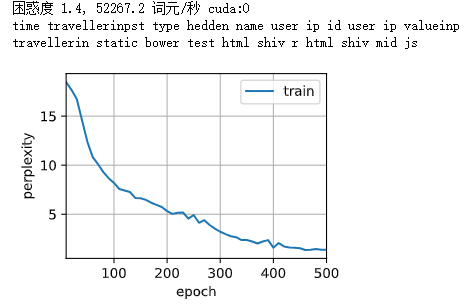
简洁实现
|
|
定义模型
|
|
|
|